Bundling?
It’s a verb I’ve taken from ”Glaser, H., Millard, I., Jaffri, A., Lewy, T. and Dowling, B. (2008) On Coreference and The Semantic Web http://eprints.ecs.soton.ac.uk/15765/” where the core idea is that you have a number of URIs that mean or reference the same real thing, and the technique they describe of bundling is to aggregate all those references together. The manner in which they describe is built on a sound basis in logic, and is related to (if not the same as) a congruent closure.
The notion of bundling I am using is not as rooted in terms of mathematical logic, because I need to convey an assertion that one URI is meant to represent the same thing that another URI represents in a given context and for a given reason. This is a different assertion, if only subtly different, than ‘owl:sameas’ asserts, but the difference is key for me.
It is best to think through an example of where I am using this – curating bibliographic records and linking authors together.
It’s an obvious desire – given a book or article, to find all the other works by an author of that said work. Technologically, with RDF this is a very simple proposition BUT the data needs to be there. This is the point where we come unstuck. We don’t really have that quality of data that firmly establishes that one author is the same as a number of others. String matching is not enough!
So, how do we clean up this data (converted to RDF) so that we can try to stitch together the authors and other entities in them?
See this previous post on augmenting British Library metadata so that the authors, publishers and so on are externally reference-able once they are given unique URIs. This really is the key step. Any other work that can be done to make any of the data about the authors and so on more semantically reference-able will be a boon to the process of connecting the dots, as I have done for authors with birth and/or death dates.
The fundamental aspect to realise is that we are dealing with datasets which have missing data, misrepresented data (typos), misinterpreted fields (ISBNs of £2.50 for example) and other non-uniform and irregular problems. Connecting authors together in datasets with these characteristics will rely on us and code that we write making educated guesses, and probabilistic assertions, based on how confident we are that things match and so on.
We cannot say for sure that something is a cast-iron match, only that we are above a certain limit of confidence that this is so. We also have to have a good reason as well.
Something else to take on board is that what I would consider to be a good match might not be good for someone else so there needs to be a manner to state a connection and to say why, who and how this match was made as well as a need to keep this data made up of assertions away from our source data.
I’ve adopted the following model for encoding this assertion in RDF, in a form that sits outside of the source data, as a form of overlay data and you can find the bundle ontology I’ve used at http://purl.org/net/bundle.rdf (pay no attention to where it is currently living):
Click to view in full, unsquished form:
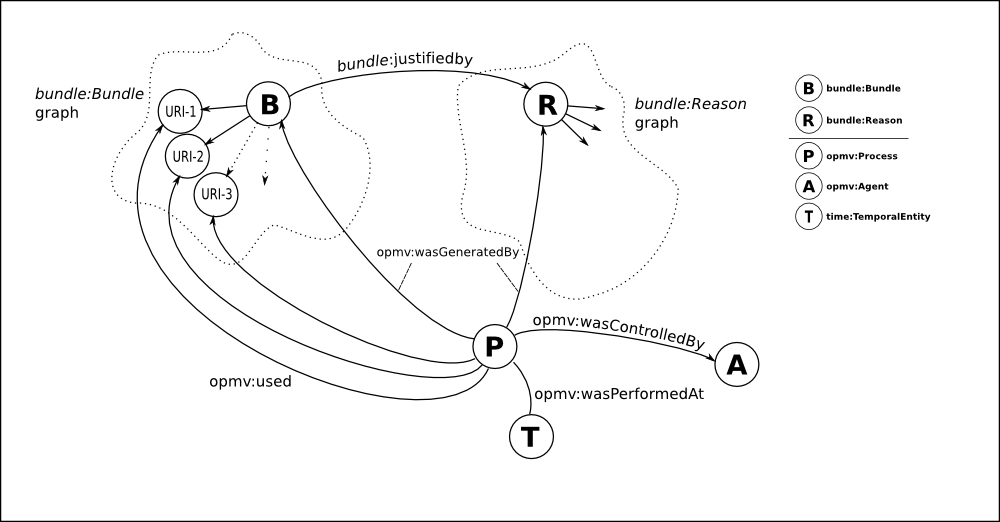
The URIs shown to be ‘opmv:used’ in this diagram are not meant to be exhaustive. It is likely that a bundle may depend on a look-up or resolution service, external datasheets, authority files, csv lists, dictionary lists and so on.
Note that the ‘Reason’ class has few, if any, mandatory properties aside from its connection to a given Bundle and opmv:Process. Assessing if you trust a Bundle at this moment is very much based on the source and the agent that made the assertion. As things get more mature, more information will regularly find its place attached to a ‘Reason’ instance.
There are currently two subtypes of Reason: AlgorithmicReason and AgentReason. Straightforwardly, this is the difference between a machine-made match and a human-made match and use of these should aid the assessment of a given match.
Creating a bundle using python:
I have added a few classes to Will Waites’ excellent ‘ordf’ library, and you can find my version here. To create a virtualenv to work within, do as follows. You will need mercurial and virtualenv already installed:
At a command line – eg ‘[@localhost] $’, enter the following:
hg clone http://bitbucket.org/beno/ordf
virtualenv myenv
. ./myenv/bin/activate
(myenv) $ pip install ordf
So, creating a bundle of some URIs – “info:foo” and “info:bar”, due to a human choice of “They look the same to me :)”:
In python: code here
from ordf.vocab.bundle import Bundle, Reason, AlgorithmicReason, AgentReason
from ordf.vocab.opmv import Agent
from ordf.namespace import RDF, BUNDLE, OPMV, DC # you are likely to use these yourself
from ordf.term import Literal, URIRef # when adding arbitrary triples
b = Bundle()
"""or if you don't want a bnode for the Bundle URI: b = Bundle(identifier="http://example.org/1")"""
"""
NB this also instantiates empty bundle.Reason and opmv.Process instances too
in b.reason and b.process which are used to create the final combined graph at the end"""
b.encapsulate( URIRef("info:foo"), URIRef("info:bar") )
""" we don't want the default plain Reason, we want a human reason:"""
r = AgentReason()
""" again, pass a identifier="" kw to set the URI if you wish"""
r.comment("They look the same to me :)")
"""Let them know who made the assertion:"""
a = Agent()
a.nick("benosteen")
a.homepage("http://benosteen.com")
""" Add this agent as the controller of the process:"""
b.process.agent(a)
g = b.bundle_graph() # this creates an in-memory graph of all the triples required to assert this bundle
""" easiest way to get it out is to "serialize" it:"""
print g.serialize()
==============
Output:
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF
xmlns:bundle="http://purl.org/net/bundle#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
xmlns:opmv="http://purl.org/net/opmv/ns#"
xmlns:ordf="http://purl.org/NET/ordf/"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
>
<rdf:Description rdf:nodeID="PZCNCkfJ2">
<rdfs:label> on monster (18787)</rdfs:label>
<ordf:hostname>monster</ordf:hostname>
<ordf:pid rdf:datatype="http://www.w3.org/2001/XMLSchema#integer">18787</ordf:pid>
<opmv:wasControlledBy rdf:nodeID="PZCNCkfJ9"/>
<ordf:version rdf:nodeID="PZCNCkfJ4"/>
<rdf:type rdf:resource="http://purl.org/net/opmv/ns#Process"/>
<ordf:cmdline></ordf:cmdline>
</rdf:Description>
<rdf:Description rdf:nodeID="PZCNCkfJ0">
<bundle:encapsulates rdf:resource="info:bar"/>
<bundle:encapsulates rdf:resource="info:foo"/>
<bundle:justifiedby rdf:nodeID="PZCNCkfJ5"/>
<opmv:wasGeneratedBy rdf:nodeID="PZCNCkfJ2"/>
<rdf:type rdf:resource="http://purl.org/net/bundle#Bundle"/>
</rdf:Description>
<rdf:Description rdf:nodeID="PZCNCkfJ5">
<rdf:type rdf:resource="http://purl.org/net/bundle#Reason"/>
<opmv:wasGeneratedBy rdf:nodeID="PZCNCkfJ2"/>
</rdf:Description>
<rdf:Description rdf:nodeID="PZCNCkfJ9">
<foaf:nick>benosteen</foaf:nick>
<rdf:type rdf:resource="http://xmlns.com/foaf/0.1/Agent"/>
<foaf:homepage rdf:resource="http://benosteen.com"/>
</rdf:Description>
<rdf:Description rdf:nodeID="PZCNCkfJ4">
<rdfs:label>ordf</rdfs:label>
<rdf:value>0.26.391.901cf0a0995c</rdf:value>
</rdf:Description>
</rdf:RDF>
Given a triplestore with these bundles, you can query for ‘same as’ URIs via which Bundles a given URI appears in.



