Bibliographic data has long been understood to contain important information about the large scale structure of scientific disciplines, the influence and impact of various authors and journals. Instead of a relatively small number of privileged data owners being able to manage and control large bibliographic data stores, we want to enable an individual researcher to browse millions of records, view collaboration graphs, submit complex queries, make selections and analyses of data – all on their laptop while commuting to work. The software tools for such easy processing are not yet adequately developed, so for the last year we have been working to improve that: primarily by acquiring open datasets upon which the community can operate, and secondarily by demonstrating what can be done with these open datasets.
Our primary product is Open Bibliographic data
Open Bibliography is a combination of Open Source tools, Open specifications and Open bibliographic data. Bibliographic data is subject to a process of continual creation and replication. The elements of bibliographic data are facts, which in most jurisdictions cannot be copyrighted; there are few technical and legal obstacles to widespread replication of bibliographic records on a massive scale – but there are social limitations: whether individuals and organisations are adequately motivated and able to create and maintain open bibliographic resources.
Open bibliographic datasets
| Source | Description | Availability |
|---|---|---|
| Cambridge University Library | This dataset consists of MARC 21 output in a single file, comprising around 180000 records. More info… | get the data |
| British Library | The British National Bibliography contains about 3 million records – covering every book published in the UK since 1950. More info… | get the data query the data |
| International Union of Crystallography | Crystallographic research journal publications metadata from Acta Cryst E. More info… | get the data query the data view the data |
| PubMed | The PubMed Medline dataset contains about 19 million records, representing roughly 98% of PubMed publications. More info… | get the data view the data |
Open bibliographic principles
In working towards acquiring these open bibliographic datasets, we have clarified the key principles of open bibliographic data and set them out for others to reference and endorse. We have already collected over 100 endorsements, and we continue to promote these principles within the community. Anyone battling with issues surrounding access to bibliographic data can use these principles and the endorsements supporting them to leverage arguments in favour of open access to such metadata.
Products demonstrating the value of Open Bibliography
OpenBiblio / Bibliographica

Bibliographica is an open catalogue of books with integrated bibliography tools for example to allow you to create your own collections and work with Wikipedia. Search our instance to find metadata about anything in the British National Bibliography. More information is available about the collections tool and the Wikipedia tool.
Bibliographica runs on the open source openbiblio software, which is designed for others to use – so you can deploy your own bibliography service and create open collections. Other significant features include native RDF linked data support, queryable SOLR indexing and a variety of data output formats.
Visualising bibliographic data
Traditionally, bibliographic records have been seen as a management tool for physical and electronic collections, whether institutional or personal. In bulk, however, they are much richer than that because they can be linked, without violation of rights, to a variety of other information. The primary objective axes are:
- Authors. As well as using individual authors as nodes in a bibliographic map, we can create co-occurrence of authors (collaborations).
- Authors’ affiliation. Most bibliographic references will now allow direct or indirect identification of the authors’ affiliation, especially the employing institution. We can use heuristics to determine where the bulk of the work might have been done (e.g. first authorship, commonality of themes in related papers etc. Disambiguation of institutions is generally much easier than for authors, as there is a smaller number and there are also high-quality sites on the web (e.g. wikipedia for universities). In general therefore, we can geo-locate all the components of a bibliographic record.
- Time. The time of publication is well-recorded and although this may not always indicate when the work was done, the pressure of modern science indicates that in many cases bibliography provides a fairly accurate snapshot of current research (i.e. with a delay of perhaps one year).
- Subject. Although we cannot rely on access to abstracts (most are closed), the title is Open and in many subjects gives high precision and recall. Currently, our best examples are in infectious diseases, where terms such as malaria, plasmodium etc. are regularly and consistently used.
With these components, it is possible to create a living map of scholarship, and we show three examples carried out with our bibliographic sets.
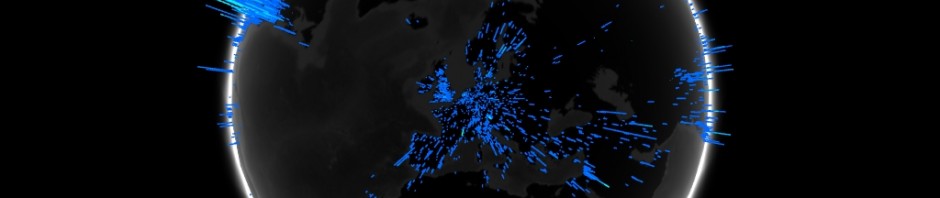
This is a geo-temporal bibliography from the full Medline dataset. Bibliographic records have been extracted by year and geo-spatial co-ordinates located on a grid. The frequency of publications in each grid square is represented by vertical bars. (Note: Only a proportion of the entries in the full dataset have been used and readers should not draw serious conclusions from this prototype). (A demonstration screencast is available at http://vimeo.com/benosteen/medline; the full interactive resource is accessible with Firefox 4 or Google Chrome, at http://benosteen.com/globe.)

This example shows a citation map of papers recursively referencing Wakefield’s paper on the adverse effects of MMR vaccination. A full analysis requires not just the act of citation but the sentiment, and initial inspection shows that the immediate papers had a negative sentiment i.e. were critical of the paper. Wakefield’s paper was eventually withdrawn but the other papers in the map still exist. It should be noted that recursive citation can often build a false sense of value for a distantly-cited object.

This is a geo-temporal bibliographic map for crystallography. The IUCr’s Open Access articles are an excellent resource as their bibliography is well-defined and the authors and affiliations well-identified. The records are plotted here on an interactive map where a slider determines the current timeslice and plots each week’s publications on a map of the world. Each publication is linked back to the original article. (The full interactive resource is available at http://benosteen.com/timemap/index.)
These visualisations show independent publications, but when the semantic facets on the data have been extracted it will be straightforward to aggregate by region, by date and to create linkages between locations.
Open bibliography for Science, Technology and Medicine
We have made further efforts to advocate for open bibliographic data by writing a paper on the subject of Open Bibliography for Science, Technology and Medicine. In addition to submitting for publication to a journal, we have
made the paper available as a prototype of the tools we are now developing. Although somewhat subsequent to the main development of this project, these examples show where this work is taking us – with large collections available, and agreement on what to expect in terms of open bibliographic data, we can now support the individual user in new ways.
Uses in the wider community
Demonstrating further applications of our main product, we have identified other projects making use of the data we have made available. These act as demonstrations for how others could make use of open bibliographic data and the tools we (or others) have developed on top of them.
Public Domain Works is an open registry of artistic works that are in the public domain. It was originally created with a focus on sound recordings (and their underlying compositions) because a term extension for sound recordings was being considered in the EU. However, it now aims to cover all types of cultural works, and the British National Bibliography data queryable via http://bibliographica.org provides an exemplar for books. The Public Domain Works team have built on our project output to create another useful resource for the community – which could not exist without both the open bibliographic data and the software to make use of it.
The Bruce at Brunel project was also able to make use of the output of the JISC Open Bibliography project; in their work to develop faceted browse for reporting, they required large quality datasets to operate on, and we were able to provide the open Medline dataset for this purpose. This is a clear advantage for having such open data, in that it informs further developments elsewhere. Additionally, in sharing these datasets we can receive feedback on the usefulness of the conversions we provide.
A further example involves the OKF Open Data in Science working group; Jenny Molloy is organising a hackathon as part of the SWAT4LS conference in December 2011, with the aim of generating open research reports using bibliographic data from PubMedCentral, focussing on malaria research. It is designed to demonstrate what can be done with open data, and this example highlights the concept of targeted bibliographic collections: essentially, reading lists of all the relevant publications on a particular topic. With open access to the bibliographic metadata, we can create and share these easily, and as required.
Additionally, with easy access to such useful datasets comes serendipitous development of useful tools. For example, one of our project team developed a simple tool over the course of a weekend for displaying relevant reading lists for events at the Edinburgh International Science Festival. This again demonstrates what can be done if only the key ingredient – the data – is openly available, discoverable and searchable.
Benefits of Open Bibliography products
Anyone with a vested interest in research and publication can benefit from these open data and open software products – academic researchers from students through to professors, as well as academic administrators and software developers, are better served by having open access to the metadata that helps describe and map the environments in which they operate. The key reasons and use cases which motivate our commitment to open bibliography are:
- Access to Information. Open Bibliography empowers and encourages individuals and organisations of various sizes to contribute, edit, improve, link to and enhance the value of public domain bibliographic records.
- Error detection and correction. Community supporting the practice of Open Bibliography will rapidly add means of checking and validating the quality of open bibliographic data.
- Publication of small bibliographic datasets. It is common for individuals, departments and organisations to provide definitive lists of bibliographic records.
- Merging bibliographic collections. With open data, we can enable referencing and linking of records between collections.
- A bibliographic node in the Linked Open Data cloud. Communities can add their own linked and annotated bibliographic material to an open LOD cloud.
- Collaboration with other bibliographic organisations. Reference manager and identifier systems such as Zotero, Mendeley, CrossRef, and academic libraries and library organisations.
- Mapping scholarly research and activity. Open Bibliography can provide definitive records against which publication assessments can be collated, and by which collaborations can be identified.
- An Open catalogue of Open scholarship. Since the bibliographic record for an article is Open, it can be annotated to show the Openness of the article itself, thus bibliographic data can be openly enhanced to show to what extent a paper is open and freely available.
- Cataloguing diverse materials related to bibliographic records. We see the opportunity to list databases, websites, review articles and other information which the community may find valuable, and to associate such lists with open bibliographic records.
- Use and development of machine learning methods for bibliographic data processing. Widespread availability of open bibliographic data in machine-readable formats
should rapidly promote the use and development of machine-learning algorithms. - Promotion of community information services. Widespread availability of open bibliographic web services will make it easier for those interested in promoting the development of scientific communities to develop and maintain subject-specific community information.
Sustaining Open Bibliography
Using these products

The products of this project add strength to an ecosystem of ongoing efforts towards large scale open bibliographic (and other) collections. We encourage others to use tools such as the OpenBiblio software, and to take our visualisations as examples for further application. We will maintain our exemplars for at least one year from publication of this post, whilst the software and content remain openly available to the community in perpetuity. We would be happy to hear from members of the community interested in using our products.
Further collaborations and future work
We intend to continue to build on the output of this project; after the success of liberating large bibliographic collections and clarifying open bibliographic principles, the focus is now on managing personal / small collections. Collaborative efforts with the Bibliographic Knowledge network project have begun, and continuing development will make the aforementioned releases of large scale open bibliographic datasets directly relevant and beneficial to people in the academic community, by providing a way for individuals – or departments or research groups – to easily manage, present, and search their own bibliographic collections.
Via collaboration with the Scholarly HTML community we intend to follow conventions for embedding bibliographic metadata within HTML documents whilst also enabling collection of such embedded records into BibJSON, thus allowing embedded metadata whilst also providing additional functionality similar to that demonstrated already, such as search and visualisation. We are also working towards ensuring compatibility between ScHTML and Schema.org, affording greater relevance and usability of ScHTML data.
Success in these ongoing efforts will enable us to support large scale open bibliographic data, providing a strong basis for open scholarship in the future. We hope to attract further support and collaboration from groups that realise the importance of Open Source code, Open Data and Open Knowledge to the future of scholarship.
Project TOC
All the posts about our project can be viewed in chronological order on our site via the jiscopenbib tag. Posts fall into three main types, and the key posts are listed below. The three types reflect the core strands of this project – documenting our progress whilst adjusting objectives for the best outcome, detailing technical development to increase awareness and for future reference, and announcing data releases. Whilst project progress and technical reports may be more common, it is very important to us to ensure also that the open dataset commitments are understood to be key events in themselves; these are the events that set the example for other groups in the publishing community, and should demonstrate open releases as the “best practice” for the community.
Project progress
- Aims and objectives
- Wider benefits
- Risk analysis
- IPR statement
- Project team and user engagement
- Timeline, workplan, methodology
- Progress report
- RLUK conference
- Dev8D conference
- Scholarly HTML
- Eurodoc conference
- Open bibliographic data from PMC
- Openbiblio workshop report
- Final product post
Technical reports
- Introducing OFS
- Bibliographic models in RDF
- Disambiguation, deduplication, and ideals
- Data triage notes
- URI patterns for a service
- Using the ORDF Fresnel tool
- Augmenting BL RDF data
- Bundling author names without owlsameas
- Characterising the BNB
- Querying the BNB
- Using the Bibliographica SPARQL API
- Getting Bibliographica content via jQuery
- Bibliographica and the EISF
- Comparative serialisation of RDF in JSON
- Follow up to serialising RDF in JSON
- Bibliographica gadget in Wikipedia
- Collections in Bibliographica
Data releases
- Cambridge University Library data release
- British Library data release
- International Union of Crystallography data release
- Open bibliographic principles announced
- Announcing the Medline dataset
Further information
Project particulars
This project started on 14th June 2010 and finished successfully and on time on 30th June 2011, with a total cost of £77050. This project was funded by JISC under the jiscEXPO stream of the INF11 programme. The PIMS URL for this project is https://pims.jisc.ac.uk/projects/view/1867.
Software and documentation links and licenses
The main software output of this project is the further developed OpenBiblio software, which is available with installation documentation at http://bitbucket.org/okfn/openbiblio. However, there were other developments done as further demonstrations over the course of the project, and each is detailed on the project blog. See the Project TOC Technical reports list for further information
All the data that was released during this project fell under OKD compliant licenses such as PDDL or CC0, depending on that chosen by the publisher, and detailed in the aforementioned announcement posts.
The content of this site is licensed under a Creative Commons Attribution 3.0 License (all jurisdictions).

Project team
- Peter Murray-Rust – Principal Investigator
- Rufus Pollock – Project manager
- Ben O’Steen – Technical lead
- Mark MacGillivray – Project management
- Will Waites – Software developer
- Richard Jones – Additional software development
- Tatiana De La O – Additional software development
And with thanks to David Flanders – JISC Program Manager
Project partners



![]()
Pingback: PabloG » Blog Archive » links for 2011-07-22
Correction on this text:
PubMed Central (PMC) is not the same as PubMed. What you are talking about here are PubMed records and PubMed publications, not PMC.
Pingback: Final Product Post: Open Bibliography | Open bibliography and Open Bibliographic Data | Open Research & Learning | Scoop.it
Pingback: Digital Infrastructure Team
Pingback: Final report: JISC Open Bibliography 2
Pingback: Final report: JISC Open Bibliography 2 | archaeoinaction.info